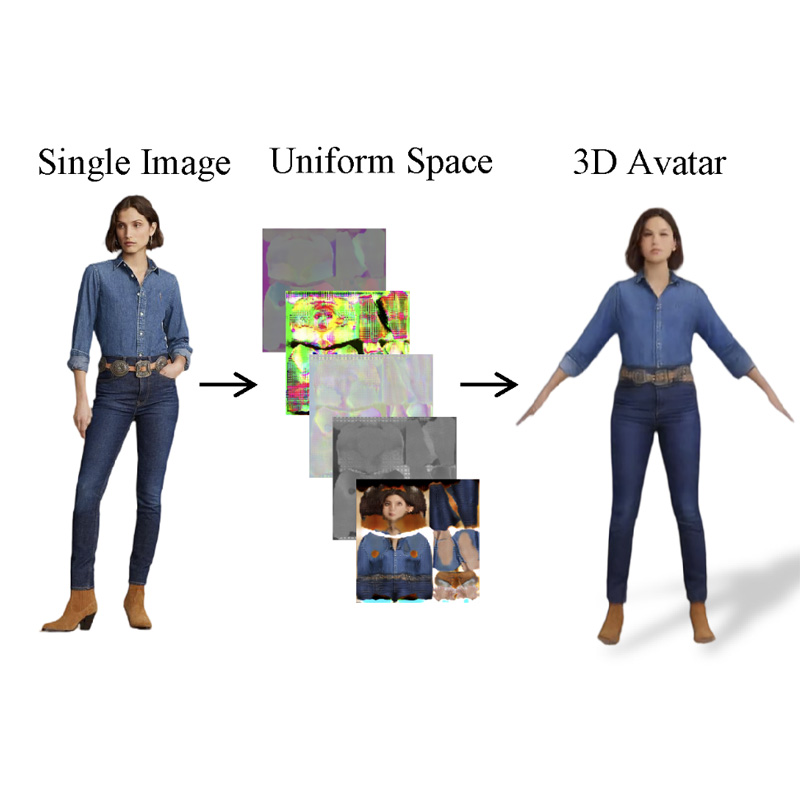
We introduce a large-scale HUman-centric GEnerated dataset, HuGe100K. Leveraging the diversity in views, poses, and appearances within HuGe100K, we propose a scalable feed-forward transformer model to predict a 3D human Gaussian representation in a uniform space from a given human image.
CVPR 2025 Project Page Code