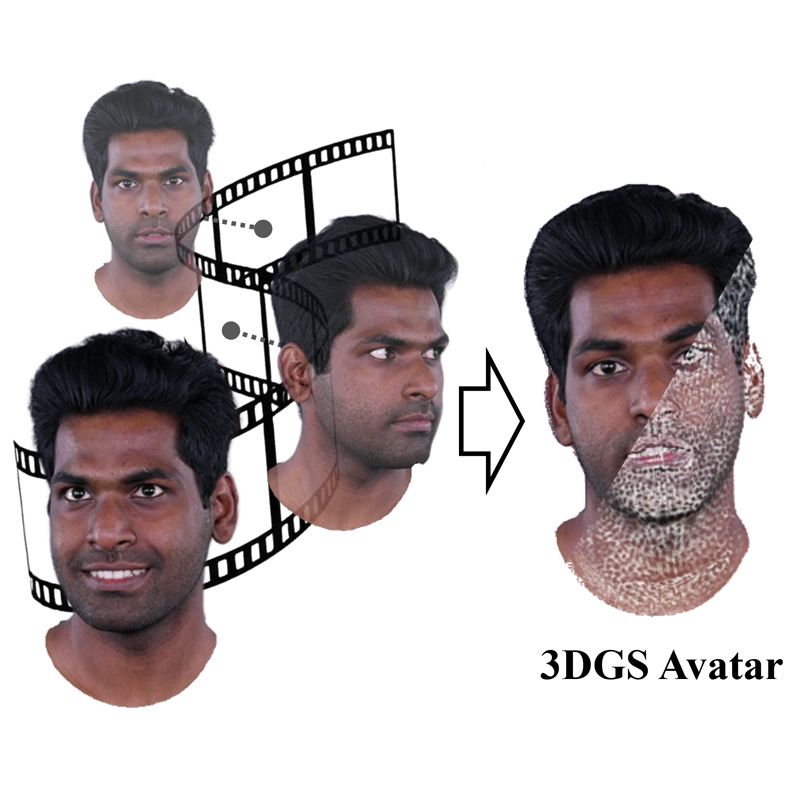
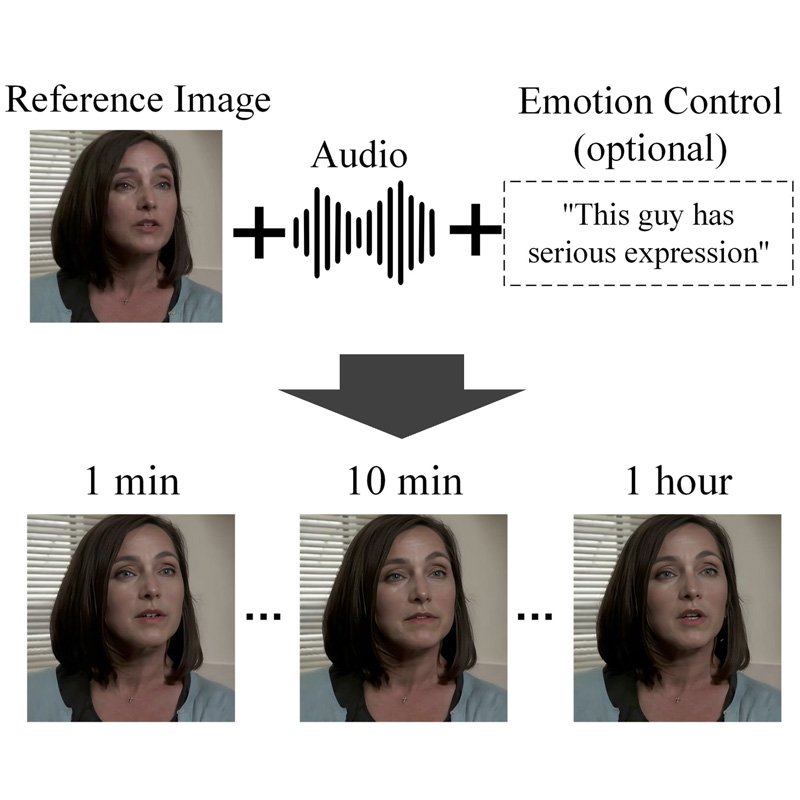
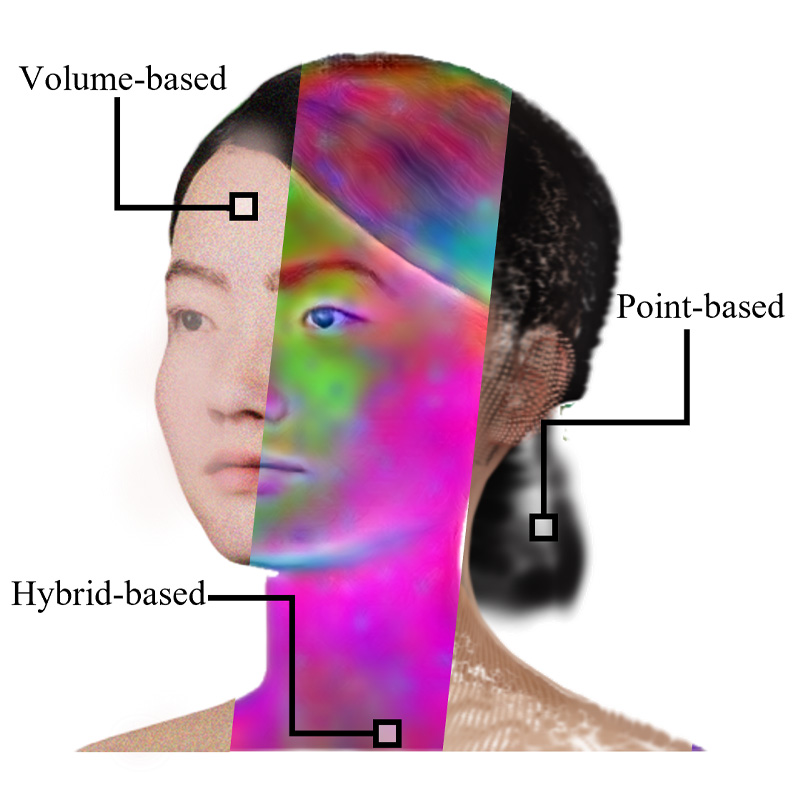
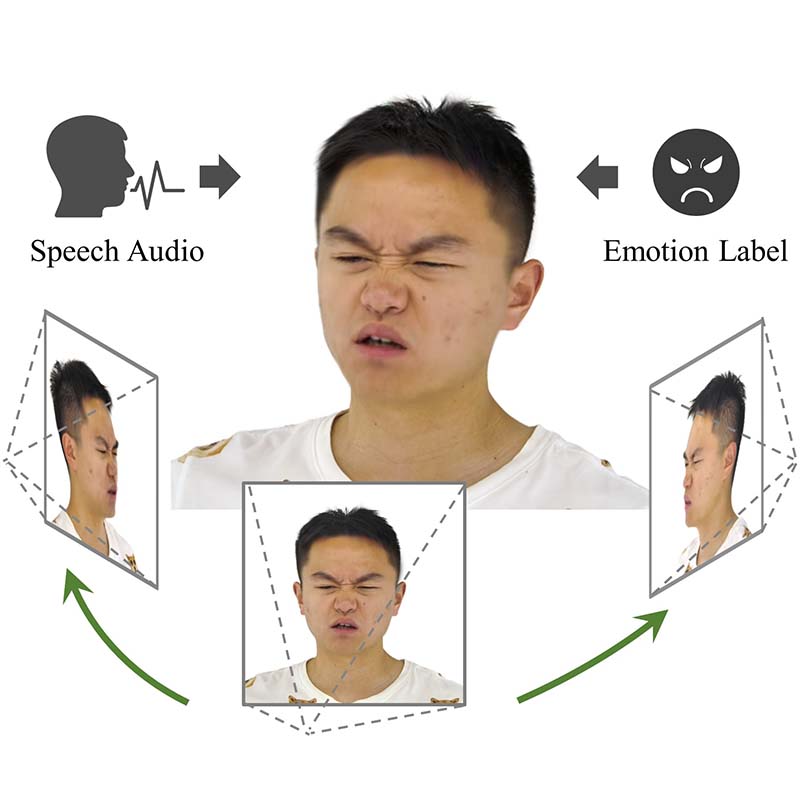
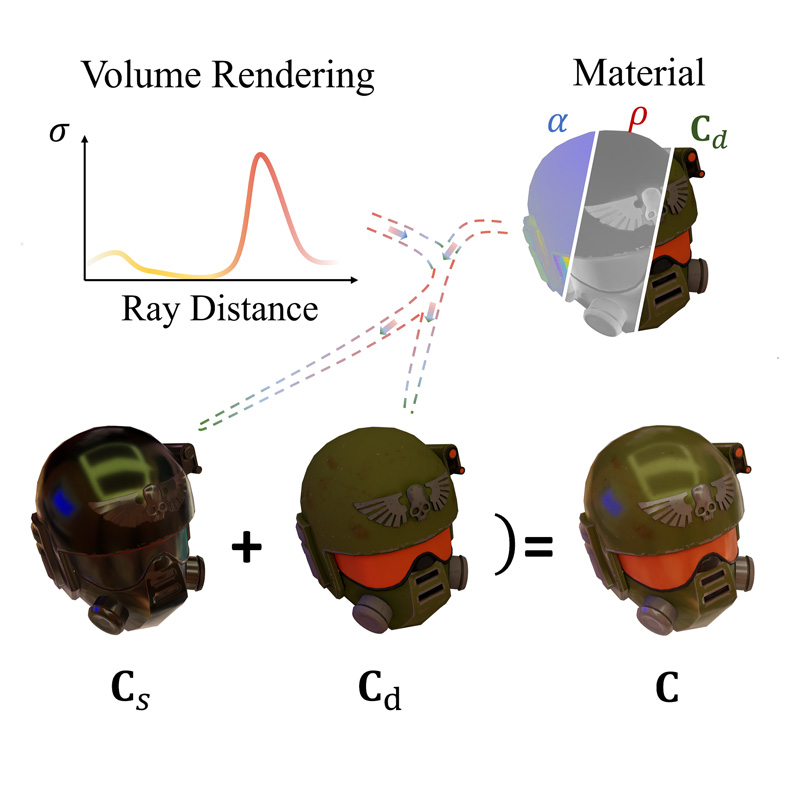
FATE introduces the first framework for reconstructing 360° animatable full-head avatars from monocular video by utilizing a sampling-based densification strategy, neural baking for intuitive editing, and a universal completion framework to achieve state-of-the-art rendering and geometric completeness.
CVPR 2025 Project Page Code